
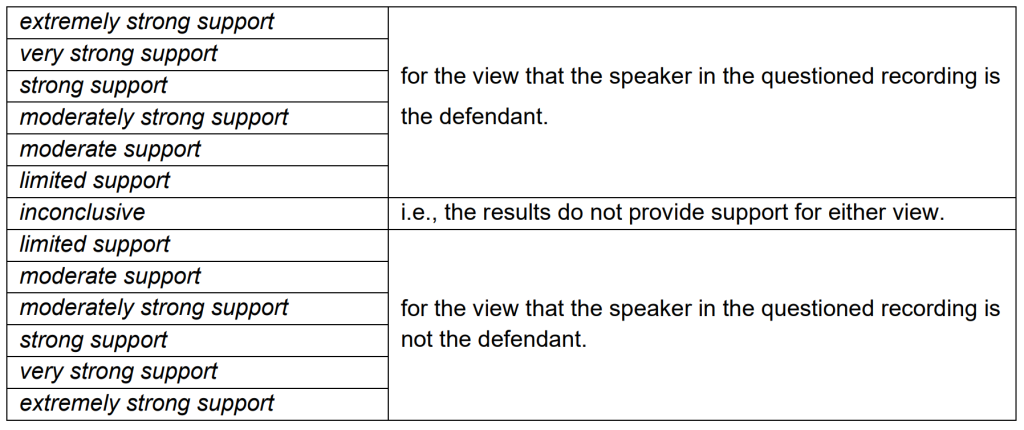
In our reports for speaker comparison cases, we present our conclusion on a 13-point scale.
The scale has six levels of support for a positive conclusion, i.e., speakers are the same person, and six levels of support for a negative conclusion, i.e., the speakers are different people.
The mid-point of the scale is inconclusive. If the outcome is inconclusive, this means that the results of analysis do not support either the ‘same speaker’ view or the ‘different speaker’ view – they are neutral.
Speaker comparison produces defensible scientific evidence and is often important in legal cases. However, it cannot provide the same strength of evidence as DNA. We make the limitations of the analyses clear in our reports and recommend that this evidence is used in conjunction with other evidence, as recommended by the International Association for Forensic Phonetics and Acoustics (IAFPA).
Conclusions are interpretative, i.e. they are based on the opinion and judgment of the experts. They are generated on the basis of the analyst’s specialist education, training and experience of analysing speech, rather than by numerical/statistical testing using a database. The conclusions in each case are checked and agreed between two experts – the reporting analyst who analyses the samples, and a checker who reviews these findings.
The conclusions are based on the degree of similarity between the reference and questioned samples, as well as the typicality or distinctiveness of the features found in the questioned samples. For example, a comparison which found very different features might produce ‘strong support for the view that the speaker in the questioned recording is not the defendant’. A comparison which found similarities between samples which were moderately distinctive might produce ‘moderate’ or ‘moderately strong’ support for the view that the speaker in the questioned recording is the defendant, whereas a comparison which found combinations of highly distinctive features might produce ‘very strong support’ for the view that the speaker in the questioned recording is the defendant.
It is not possible to estimate what the conclusion of a comparison might be until the analysis has been completed and checked. In some cases, it might be possible to determine from a screening that the conclusions are likely to be limited.